HTML to PDF conversion is a common requirement in C# applications. It is often used to generate invoices, reports, contracts, shipping labels, and other business documents from HTML templates or live web pages.

There are several ways to convert HTML to PDF in C#, but choosing the right tool depends on what you need. Some libraries are better for simple HTML strings, while others are much better at rendering modern web pages with JavaScript, CSS, and browser-like output.
In this guide, we will look at 5 popular ways to convert HTML to PDF in C#. We will compare their strengths, limitations, and typical use cases so you can choose the best option for your project. We will also show when it makes sense to use an HTML to PDF API instead of managing the rendering infrastructure yourself.
If you want reliable output for modern HTML and CSS, browser-based tools are usually the strongest choice. If you want a faster setup with less maintenance, an API can be a practical alternative.
Let’s get started.
1. Why using HTML for PDF conversion
i. Open and Mature Technology: HTML is an open standard, ensuring that the tools and technologies developed around it are widely available and well-understood. Its maturity signifies that most challenges and peculiarities have been thoroughly documented, making troubleshooting easier.
ii. Cost-effective: A wide range of tools, libraries, and APIs (both free and paid) are available to convert HTML to PDF. This diminishes the need for specialized PDF creation software.
iii. Embed Multimedia: HTML facilitates embedding multimedia elements like images, videos, and audios. Although not all these elements can be directly converted to PDF, using HTML as a source offers opportunities to create documents enriched with multimedia.
iv. Styling with CSS: Cascading Style Sheets (CSS) offer robust styling capabilities for HTML content. This enables effective branding, theming, and visual consistency, which are then mirrored in the resultant PDF.
v. Easy to Learn and Use: Learning the basics of HTML is straightforward, making it accessible for many users to generate content.
In summary, converting HTML to PDF combines the best aspects of both formats: the flexibility, accessibility, and interactivity of HTML with the portability and standardization of PDFs.
2. Converting HTML to PDF using C# Popular Libraries
i. PuppeteerSharp
PuppeteerSharp is a .NET port of Puppeteer that provides a high-level API to control headless browsers. PuppeteerSharp is used to scrape web content, automate testing, generate PDFs, or take screenshots of websites. With PuppeteerSharp, you can easily convert HTML to PDF or website to PDF.
Generate PDF from a website URL
using System.Threading.Tasks;
using PuppeteerSharp;
class Program
{
public static async Task Main()
{
await new BrowserFetcher().DownloadAsync();
using var browser = await Puppeteer.LaunchAsync(new LaunchOptions { Headless = true });
var page = await browser.NewPageAsync();
await page.GoToAsync("http://www.google.com");
await page.PdfAsync("website.pdf");
}
}
In the above code, we are doing the following:
- The
BrowserFetcherdownloads the required version of Chromium. Puppeteer.LaunchAsyncstarts a headless browser instance where we pass our website URL.NewPageAsynccreates a new tab.- We use
GoToAsyncto navigate to our website URL. - Finally,
PdfAsyncgenerates the PDF from the website’s current state.
Generate PDF from Custom HTML content
using System.Threading.Tasks;
using PuppeteerSharp;
class Program
{
public static async Task Main()
{
await new BrowserFetcher().DownloadAsync();
using var browser = await Puppeteer.LaunchAsync(new LaunchOptions { Headless = true });
using var page = await browser.NewPageAsync();
await page.SetContentAsync("<div>My Custom Content</div>");
await page.PdfAsync("customContent.pdf");
}
}
In the above code, we are generating PDFs from custom HTML content:
BrowserFetcherdownloads a new instance of Chromium.- We then launch this instance as a headless browser.
- A new page is created in our headless browser with
NewPageAsync, where we set our custom HTML content. - Finally,
PdfAsyncis used to generate the PDF from the custom HTML content set on the page.
ii. HtmlRenderer.PdfSharp
HtmlRenderer.PdfSharp is a C# library used to generate PDFs. This library enables the creation of PDF documents from HTML snippets using static rendering code.
While HtmlRenderer.PdfSharp doesn’t support generating PDFs directly from website URLs by default, we can first extract the website content and then utilize the library for PDF generation.
Convert Website to PDF
using System;
using System.Net;
using PdfSharp;
using TheArtOfDev.HtmlRenderer.PdfSharp;
class Program
{
static void Main()
{
using (var client = new WebClient())
{
string htmlCode = client.DownloadString("http://example.com");
PdfDocument pdf = PdfGenerator.GeneratePdf(htmlCode, PageSize.A4);
pdf.Save("url_to_pdf.pdf");
}
}
}
In the above code, we are performing the following steps to generate a PDF:
Since this library does not support direct URL content fetching, we use
WebClientto get the content from the website URL.We extract the website content from the URL using
client.DownloadString.Using
PdfGenerator.GeneratePdf, we generate the PDF with the extracted content.Finally, we download the content.
Generate PDF from Custom HTML content
using System;
using PdfSharp;
using TheArtOfDev.HtmlRenderer.PdfSharp;
namespace html_to_pdf
{
class Program
{
static void Main(string[] args)
{
string htmlString = "<h1>Document</h1> <p>This is an HTML document which is converted to a pdf file.</p>";
PdfDocument pdfDocument = PdfGenerator.GeneratePdf(htmlString, PageSize.A4);
pdfDocument.Save("html_to_pdf.pdf");
}
}
}
To generate PDFs from custom HTML content, we follow a similar approach. The only difference is that we now use our custom HTML content as the extracted content.
iii. iTextSharp
iTextSharp is a widely-used .NET library for creating and manipulating PDF documents. It allows developers to generate PDFs from different sources, including HTML content.
However, iTextSharp does not automatically fetch HTML content from URLs. its main function is to convert provided HTML content into PDFs.
Convert Website to PDF
using System;
using System.IO;
using System.Net;
using iTextSharp.text;
using iTextSharp.text.pdf;
using iTextSharp.text.html.simpleparser;
class Program
{
static void Main()
{
string htmlContent;
using (var client = new WebClient())
{
htmlContent = client.DownloadString("http://example.com");
}
using (var memoryStream = new MemoryStream())
{
using (var document = new Document())
{
PdfWriter writer = PdfWriter.GetInstance(document, memoryStream);
document.Open();
using (var stringReader = new StringReader(htmlContent))
{
HTMLWorker htmlParser = new HTMLWorker(document);
htmlParser.Parse(stringReader);
}
document.Close();
}
// Save PDF to file
File.WriteAllBytes("website.pdf", memoryStream.ToArray());
}
}
}
iTextSharp does not support generating PDFs directly from URLs out of the box.
First, we extract the website content using
WebClient.We then use
HTMLWorkerto insert the content into a PDF instance created byPdfWriter.Finally, we download the generated PDF.
Generate PDF from Custom HTML content
using System;
using System.IO;
using iTextSharp.text;
using iTextSharp.text.pdf;
using iTextSharp.text.html.simpleparser;
class Program
{
static void Main()
{
string htmlContent = "<h1>Hello World</h1><p>This is a test HTML string.</p>";
using (var memoryStream = new MemoryStream())
{
using (var document = new Document())
{
PdfWriter writer = PdfWriter.GetInstance(document, memoryStream);
document.Open();
using (var stringReader = new StringReader(htmlContent))
{
HTMLWorker htmlParser = new HTMLWorker(document);
htmlParser.Parse(stringReader);
}
document.Close();
}
File.WriteAllBytes("customHtmlContent.pdf", memoryStream.ToArray());
}
}
}
Generating PDFs from custom HTML is similar to generating them from website content. In this case, we directly obtain the HTML content without using WebClient. We then follow similar steps to create the PDFs.
iv. PlayWright
Playwright is a modern automation library that provides capabilities for running browser instances programmatically.
Originally designed for testing web applications, Playwright‘s functionality extends well beyond testing, offering tools for web scraping, automation, and, notably, PDF generation. In C#,
Playwright can be used to control a browser, navigate to web pages, or render HTML content, and capture it as a PDF file. This capability is especially useful for generating reports, receipts, or any web content that needs to be presented in a document format.
To begin using Playwright in C#, you need to install the Playwright library along with the necessary browser binaries.
This setup involves adding the Playwright NuGet package and running a simple installation command which ensures all required components are properly set up. Here’s how you can prepare your environment:
dotnet add package Microsoft.PlaywrightYou might run into issues, please following the instructions to install the necessary browsers
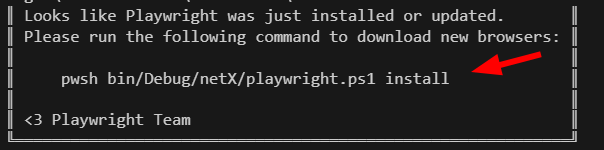
After setting up, you can write C# code to automate the browser and generate a PDF from any accessible webpage.
Convert Website to PDF
Below is an example of how you can use Playwright to capture a webpage as a PDF:
using Microsoft.Playwright;
using System.Threading.Tasks;
class Program
{
static async Task Main()
{
using var playwright = await Playwright.CreateAsync();
var browser = await playwright.Chromium.LaunchAsync(new BrowserTypeLaunchOptions
{
Headless = true // Run browser in headless mode
});
var page = await browser.NewPageAsync();
await page.GotoAsync("http://example.com");
// Save the page as a PDF file
await page.PdfAsync(new PagePdfOptions
{
Path = "website_to_pdf.pdf",
Format = "A4"
});
await browser.CloseAsync();
}
}
- Initialize Playwright: Launch the Playwright environment and start a headless browser instance. Headless browsers do not have a GUI, making them faster and more suitable for automated tasks.
- Navigate to the Webpage: Open a new page and go to the desired URL.
- Generate and Save PDF: Convert the current page into a PDF with the specified format and save it locally.
- Clean Up: Close the browser to free up resources.
Generate PDF from Custom HTML Content
You can also use Playwright to render custom HTML content into a PDF without needing an existing webpage. This is particularly useful for generating dynamic documents based on user data or application state:
using Microsoft.Playwright;
using System.Threading.Tasks;
class Program
{
static async Task Main()
{
using var playwright = await Playwright.CreateAsync();
var browser = await playwright.Chromium.LaunchAsync(new BrowserTypeLaunchOptions
{
Headless = true // Run browser in headless mode
});
var page = await browser.NewPageAsync();
await page.SetContentAsync("<h1>Document</h1> <p>This is a custom HTML content which is converted to a PDF file.</p>");
// Save the custom HTML page as a PDF file
await page.PdfAsync(new PagePdfOptions
{
Path = "html_to_pdf.pdf",
Format = "A4"
});
await browser.CloseAsync();
}
}
To generate PDFs from custom HTML content, we follow a similar approach but utilize SetContentAsync to load custom HTML directly into the page.
In both cases, Playwright offers a seamless integration with browser environments, enabling dynamic content rendering and PDF generation with high fidelity, making it a powerful tool for C# developers looking to automate document creation from web content.
v. wkhtmltopdf
wkhtmltopdf is a command line tool that converts HTML into PDF using the Qt WebKit rendering engine. This tool allows the rendering of HTML content in PDF format with high fidelity, making it a popular choice for generating PDFs in C#.
To use wkhtmltopdf in C#, you can wrap it in a system process call within your .NET application. This approach involves calling the wkhtmltopdf executable from your C# code, passing HTML content or URL directly to it.
Convert Website to PDF
To convert a website URL to a PDF using wkhtmltopdf in C#, you’ll leverage the command-line interface of wkhtmltopdf.
The process involves running the wkhtmltopdf executable with appropriate arguments. Here’s how to do it step by step:
using System;
using System.Diagnostics;
class Program
{
static void Main()
{
// Specify the URL to convert
string url = "http://example.com";
// Define the output path for the PDF file
string outputPath = "url_to_pdf.pdf";
// Configure the ProcessStartInfo for wkhtmltopdf
ProcessStartInfo startInfo = new ProcessStartInfo
{
FileName = "wkhtmltopdf",
Arguments = $"\"{url}\" \"{outputPath}\"",
UseShellExecute = false
};
// Create and start the process
using (Process process = new Process { StartInfo = startInfo })
{
process.Start();
process.WaitForExit(); // Wait for the process to complete
}
}
}
- ProcessStartInfo Configuration: Sets up the necessary parameters to run
wkhtmltopdf. TheFileNameproperty specifies the executable name, andArgumentsare constructed with the URL and the desired output file path. - Process Execution: Initiates the
wkhtmltopdfprocess, which reads the specified URL, renders the HTML content, and saves it to a PDF file at the specified location. - WaitForExit: Ensures that the execution waits until the PDF conversion is complete before moving on or ending the program.
Generate PDF from Custom HTML Content
Generating a PDF from custom HTML content involves creating a temporary file to store the HTML, which wkhtmltopdf can then process. Here’s a detailed breakdown:
using System;
using System.Diagnostics;
using System.IO;
class Program
{
static void Main()
{
// Define your custom HTML content
string htmlContent = "<h1>Title</h1><p>This is an HTML snippet converted to a PDF file.</p>";
// Create a temporary file and write the HTML content to it
string tempHtmlPath = Path.GetTempFileName();
File.WriteAllText(tempHtmlPath, htmlContent);
// Define the output path for the PDF file
string outputPath = "html_to_pdf.pdf";
// Set up the ProcessStartInfo for wkhtmltopdf
ProcessStartInfo startInfo = new ProcessStartInfo
{
FileName = "wkhtmltopdf",
Arguments = $"\"{tempHtmlPath}\" \"{outputPath}\"",
UseShellExecute = false
};
// Run the process to convert the HTML to PDF
using (Process process = new Process { StartInfo = startInfo })
{
process.Start();
process.WaitForExit(); // Ensure the process completes
}
// Clean up: Delete the temporary HTML file
File.Delete(tempHtmlPath);
}
}
- Temporary HTML File: Stores the HTML content in a temporary file. This file acts as the source for
wkhtmltopdf. - ProcessStartInfo and Process: Configures and runs
wkhtmltopdfsimilar to the URL conversion, but this time it uses the path to the temporary HTML file. - Cleanup: Deletes the temporary file to avoid leaving residual files on the filesystem.
These detailed steps ensure that both URLs and custom HTML content can be converted to PDF files in a .NET environment using wkhtmltopdf, providing a robust method for PDF generation in business applications or content management systems.
3. Comparison of All Five C# Libraries for PDF Generation
Generating PDF documents is a common requirement for many applications in the .NET environment. This article presents a comprehensive comparison of three popular libraries used in C# for PDF generation: PuppeteerSharp, HtmlRenderer.PdfSharp, iTextSharp, PlayWright, and wkhtmltopdf
This comparison aims to provide an overview of these libraries to help developers choose the right tool for their specific requirements.
| Feature | PuppeteerSharp | HtmlRenderer.PdfSharp | iTextSharp | PlayWright | wkhtmltopdf |
|---|---|---|---|---|---|
| Language/Platform | C# (.NET) | C# (.NET) | C# (.NET) | Multiple (C#, JavaScript and others) | Command Line (Cross-platform) |
| Main Use Case | Web page to PDF | HTML/CSS to PDF | PDF Creation & Manipulation | Web page to PDF | HTML to PDF |
| Rendering Engine | Chromium (via Puppeteer) | Custom PDF renderer | N/A | Chromium (via Playwright) | WebKit/Qt |
| Support for JavaScript | Yes | No | No | Yes | Yes |
| CSS Support | Full | Limited | N/A | Full | Full |
| Ease of Use | Moderate | Easy | Moderate to Complex | Moderate | Moderate |
| Performance | High | Moderate | High | High | Moderate to High |
| Documentation & Community | Good | Moderate | Excellent | Good | Good |
| License | MIT | Apache License 2.0 | AGPL | MIT | LGPL |
Which C# HTML to PDF library should you use?
- Playwright: best overall for modern websites and JavaScript-heavy pages
- PuppeteerSharp: great Chromium-based option for browser rendering
- wkhtmltopdf: useful for legacy workflows, but weaker modern CSS support
- HtmlRenderer.PdfSharp: suitable for simple HTML only
- iTextSharp: better for PDF creation/manipulation than full web-page rendering
- APITemplate.io: best when you want managed infrastructure and templates
For developers working within the .NET ecosystem, PuppeteerSharp and PlayWright offer robust solutions for rendering web pages as PDFs with full JavaScript and CSS support.
HtmlRenderer.PdfSharp, while limited in its CSS capabilities, is an excellent choice for straightforward HTML to PDF conversions.
iTextSharp stands out for its comprehensive PDF manipulation features, suitable for applications that require detailed customization of PDF documents.
Lastly, wkhtmltopdf provides a command-line solution that leverages web rendering engines, making it versatile for various environments.
By understanding the strengths and limitations of each library, developers can make informed decisions that best suit their project requirements.
4. Converting HTML to PDF using APITemplate.io
The examples above demonstrate how we can use various libraries to convert HTML and web pages to PDFs in C#.
Another way to convert HTML to PDF in C# is by using APITemplate.io. Instead of relying on self-hosted libraries and rendering tools, APITemplate.io provides an API-based workflow for generating PDFs from HTML and template data.
This can be a good choice when you want to simplify implementation and reduce the maintenance involved in running your own HTML-to-PDF pipeline.
Let’s see how we can use APITemplate.io to generate PDFs.
i. Generate Template-Based PDF
APITemplate.io allows you to manage your templates. Go to “Manage Templates” from the dashboard.
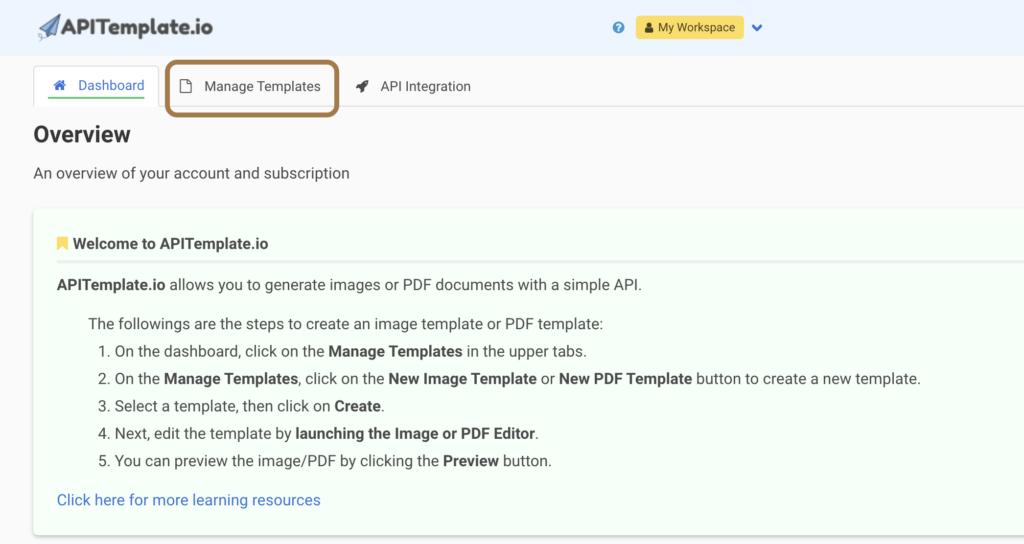
From Manage Template, you can create your own templates. The following is a sample invoice template. There are many templates available that you can choose from and customize based on your requirements.
To start using APITemplate.io APIs, you need to obtain your API Key, which can be obtained from the API Integration tab.
Now that you have your APITemplate account ready, let’s take some action and integrate it with our application. We will use the template to generate PDFs.
using System;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Threading.Tasks;
using Newtonsoft.Json;
class Program
{
static async Task Main(string[] args)
{
// API URL
string url = "https://rest.apitemplate.io/v2/create-pdf?template_id=YOUR_TEMPLATE_ID";
// Payload data
var payload = new
{
date = "15/05/2022",
invoice_no = "435568799",
sender_address1 = "3244 Jurong Drive",
sender_address2 = "Falmouth Maine 1703",
sender_phone = "255-781-6789",
sender_email = "hello@logos.com",
rece_addess1 = "2354 Lakeside Drive",
rece_addess2 = "New York 234562",
rece_phone = "34333-84-223",
rece_email = "business@apitemplate.io",
items = new[]
{
new { item_name = "Oil", unit = 1, unit_price = 100, total = 100 },
new { item_name = "Rice", unit = 2, unit_price = 200, total = 400 },
// ... Add other items here
},
total = "total",
footer_email = "hello@logos.com",
};
string jsonPayload = JsonConvert.SerializeObject(payload);
using (var client = new HttpClient())
{
client.DefaultRequestHeaders.Add("X-API-KEY", "YOUR_API_KEY");
client.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue("application/json"));
try
{
var content = new StringContent(jsonPayload, System.Text.Encoding.UTF8, "application/json");
var response = await client.PostAsync(url, content);
string responseString = await response.Content.ReadAsStringAsync();
Console.WriteLine(responseString);
}
catch (HttpRequestException e)
{
Console.Error.WriteLine($"Error: {e.Message}");
}
}
}
}
And if we check the response_string, we have the following:
{
"download_url":"PDF_URL",
"transaction_ref":"8cd2aced-b2a2-40fb-bd45-392c777d6f6",
"status":"success",
"template_id":"YOUR_TEMPLATE_ID"
}
In the above code, it’s very easy to use ApiTemplate to convert HTML to PDF because we don’t need to install any other library. We just need to call one simple API and use our data as a request body, and that’s it!
You can use the download_url from the response to download or distribute the generated PDF.
ii. Convert Website to PDF using API Template
ApiTemplate also supports generating PDFs from website URLs.
using System;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Threading.Tasks;
using Newtonsoft.Json;
class Program
{
static async Task Main()
{
const string apiKey = "YOUR_API_KEY";
const string templateId = "YOUR_TEMPLATE_ID";
var data = new
{
url = "https://en.wikipedia.org/wiki/Sceloporus_malachiticus",
settings = new
{
paper_size = "A4",
orientation = "1",
header_font_size = "9px",
margin_top = "40",
margin_right = "10",
margin_bottom = "40",
margin_left = "10",
print_background = "1",
displayHeaderFooter = true,
custom_header = @"<style>#header, #footer { padding: 0 !important; }</style>
<table style='width: 100%; padding: 0px 5px;margin: 0px!important;font-size: 15px'>
<tr>
<td style='text-align:left; width:30%!important;'><span class='date'></span></td>
<td style='text-align:center; width:30%!important;'><span class='pageNumber'></span></td>
<td style='text-align:right; width:30%!important;'><span class='totalPages'></span></td>
</tr>
</table>",
custom_footer = @"<style>#header, #footer { padding: 0 !important; }</style>
<table style='width: 100%; padding: 0px 5px;margin: 0px!important;font-size: 15px'>
<tr>
<td style='text-align:left; width:30%!important;'><span class='date'></span></td>
<td style='text-align:center; width:30%!important;'><span class='pageNumber'></span></td>
<td style='text-align:right; width:30%!important;'><span class='totalPages'></span></td>
</tr>
</table>"
}
};
var json = JsonConvert.SerializeObject(data);
using (var client = new HttpClient())
{
client.DefaultRequestHeaders.Add("X-API-KEY", apiKey);
try
{
var content = new StringContent(json, System.Text.Encoding.UTF8, "application/json");
var response = await client.PostAsync("https://rest.apitemplate.io/v2/create-pdf-from-url", content);
var responseString = await response.Content.ReadAsStringAsync();
Console.WriteLine("PDF generated successfully: " + responseString);
}
catch (HttpRequestException e)
{
Console.Error.WriteLine("Error: " + e.Message);
}
}
}
}
In the above code, we can provide the URL in the request body along with the settings for the PDF. APITemplate will use this request body to generate a PDF and return a download URL for your PDF.
iii. Generate PDF from custom HTML content
If you want to generate PDFs using your own custom HTML content, ApiTemplate also supports that.
using System;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Threading.Tasks;
using Newtonsoft.Json;
class Program
{
static async Task Main()
{
const string apiKey = "YOUR_API_KEY";
const string templateId = "YOUR_TEMPLATE_ID";
var data = new
{
body = "<h1> hello world {{name}} </h1>",
css = "<style>.bg{background: red};</style>",
data = new
{
name = "This is a title"
},
settings = new
{
paper_size = "A4",
orientation = "1",
header_font_size = "9px",
margin_top = "40",
margin_right = "10",
margin_bottom = "40",
margin_left = "10",
print_background = "1",
displayHeaderFooter = true,
custom_header = @"<style>#header, #footer { padding: 0 !important; }</style>
<table style='width: 100%; padding: 0px 5px;margin: 0px!important;font-size: 15px'>
<tr>
<td style='text-align:left; width:30%!important;'><span class='date'></span></td>
<td style='text-align:center; width:30%!important;'><span class='pageNumber'></span></td>
<td style='text-align:right; width:30%!important;'><span class='totalPages'></span></td>
</tr>
</table>",
custom_footer = @"<style>#header, #footer { padding: 0 !important; }</style>
<table style='width: 100%; padding: 0px 5px;margin: 0px!important;font-size: 15px'>
<tr>
<td style='text-align:left; width:30%!important;'><span class='date'></span></td>
<td style='text-align:center; width:30%!important;'><span class='pageNumber'></span></td>
<td style='text-align:right; width:30%!important;'><span class='totalPages'></span></td>
</tr>
</table>"
}
};
var json = JsonConvert.SerializeObject(data);
using (var client = new HttpClient())
{
client.DefaultRequestHeaders.Add("X-API-KEY", apiKey);
try
{
var content = new StringContent(json, System.Text.Encoding.UTF8, "application/json");
var response = await client.PostAsync("https://rest.apitemplate.io/v2/create-pdf-from-html", content);
var responseString = await response.Content.ReadAsStringAsync();
Console.WriteLine("PDF generated successfully: " + responseString);
}
catch (HttpRequestException e)
{
Console.Error.WriteLine("Error: " + e.Message);
}
}
}
}
Similar to generating a PDF from a website URL, the API request above takes the body and CSS as part of the payload to generate a PDF.
5. Performance Considerations
Open source third-party libraries are generally effective for most needs. Yet, for generating PDFs from HTML on a large scale, managing scaling and various edge cases becomes your responsibility.
With APITemplate.io, these concerns about performance and scaling are taken care of for you. APITemplate.io also handles error situations, providing a more streamlined and reliable solution for large-scale PDF generation.
6. Conclusion
PDF generation has become an essential feature in modern business applications. We’ve explored using third-party libraries for simple PDF generation tasks.
For teams that prefer a hosted approach, our guide to the best PDF generation APIs compares popular API-based options for automating PDF generation.
For more complex scenarios, like managing templates, APITemplate.io offers a tailored solution through straightforward API calls. This approach simplifies handling intricate use cases, providing a user-friendly alternative for complex PDF generation requirements.
Sign up for a free account with us now and start automating your PDF generation.
FAQ
What is the best C# library to convert HTML to PDF?
The best C# library for HTML to PDF conversion depends on your use case. If you need to render modern HTML, CSS, and JavaScript accurately, Playwright is usually one of the best choices because it uses a real browser engine. PuppeteerSharp is also a strong option for browser-based rendering. For simpler documents, lightweight libraries may be enough, but they often have more limitations.
How do I convert HTML to PDF in C#?
To convert HTML to PDF in C#, you typically use a library that renders HTML and exports the result as a PDF file. Some libraries work well for simple HTML strings, while browser-based tools such as Playwright and PuppeteerSharp are better for modern web pages with JavaScript and advanced CSS. The general process is to load the HTML, render it, and save or return the generated PDF.
Can C# convert a URL or web page to PDF?
Yes, C# can convert a live URL or web page to PDF. This is commonly done with browser-based tools such as Playwright or PuppeteerSharp, which load the page in a headless browser and then export it as a PDF. This approach is useful when you want the PDF to closely match how the page appears in a real browser.
Which C# HTML to PDF library supports JavaScript?
Browser-based libraries such as Playwright and PuppeteerSharp support JavaScript rendering because they use Chromium under the hood. This makes them a good choice for pages that rely on client-side frameworks, dynamic content, or delayed rendering. Simpler HTML to PDF libraries may not fully support JavaScript, which can lead to missing or incomplete output.
Is wkhtmltopdf still a good option for C# PDF generation?
wkhtmltopdf can still be useful for some projects, especially older workflows that already depend on it, but it is no longer the best default choice for many modern applications. Its rendering engine is older, so it may struggle with newer CSS features and JavaScript-heavy pages. For better compatibility with modern websites, Playwright or PuppeteerSharp is often the better option.
Can I convert Razor views to PDF in ASP.NET Core?
Yes, you can convert Razor views to PDF in ASP.NET Core. A common approach is to render the Razor view into HTML first and then pass that HTML into an HTML to PDF tool. This works well for invoices, reports, certificates, and other server-generated documents where you already use Razor templates in your application.
What are the limitations of HTML to PDF conversion in C#?
HTML to PDF conversion in C# can be challenging when documents rely on modern CSS, JavaScript rendering, custom fonts, page breaks, or external assets. Some libraries do not fully support browser-like rendering, which can cause layout differences between the web page and the final PDF. At scale, you may also need to manage browser processes, performance, and infrastructure reliability.
When should I use an HTML to PDF API instead of a C# library?
You should use an HTML to PDF API when you want to avoid managing rendering engines, browser dependencies, scaling concerns, and maintenance work yourself. This can be a good option for teams that need reliable PDF generation in production without building and maintaining their own rendering pipeline. APIs are especially useful when you want a faster setup, hosted infrastructure, and a simpler integration path.